Ollama 聊天
借助 Ollama,您可以在本地运行各种大型语言模型(LLM)并从中生成文本。Spring AI 通过 OllamaChatModel API 支持 Ollama 聊天完成功能。
| Ollama 也提供一个与 OpenAI API 兼容的端点。 OpenAI API 兼容性 部分解释了如何使用 Spring AI OpenAI 连接到 Ollama 服务器。 |
先决条件
您首先需要访问一个 Ollama 实例。有几种选择,包括以下内容:
-
下载并安装 Ollama 到您的本地机器上。
-
通过 Kubernetes 服务绑定 绑定到 Ollama 实例。
您可以从 Ollama 模型库 中拉取您希望在应用程序中使用的模型。
ollama pull <model-name>您还可以拉取数千个免费的 GGUF Hugging Face 模型
ollama pull hf.co/<username>/<model-repository>或者,您可以启用自动下载所需模型的选项:自动拉取模型。
自动配置
|
Spring AI 自动配置、启动模块的工件名称发生了重大变化。请参阅 升级说明 以获取更多信息。 |
Spring AI 为 Ollama 聊天集成提供了 Spring Boot 自动配置。要启用它,请将以下依赖项添加到您的项目的 Maven pom.xml 或 Gradle build.gradle 构建文件中。
-
Maven
-
Gradle
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-ollama</artifactId>
</dependency>dependencies {
implementation 'org.springframework.ai:spring-ai-starter-model-ollama'
}| 请参阅 依赖项管理 部分,将 Spring AI BOM 添加到您的构建文件中。 |
基本属性
前缀 spring.ai.ollama 是配置与 Ollama 连接的属性前缀。
财产 |
描述 |
默认值 |
spring.ai.ollama.base-url |
Ollama API 服务器运行的基本 URL。 |
|
以下是用于初始化 Ollama 集成和自动拉取模型的属性。
财产 |
描述 |
默认值 |
spring.ai.ollama.init.pull-model-strategy |
是否在启动时拉取模型以及如何拉取。 |
|
spring.ai.ollama.init.timeout |
等待模型被拉取的时间。 |
|
spring.ai.ollama.init.max-retries |
模型拉取操作的最大重试次数。 |
|
spring.ai.ollama.init.chat.include |
在初始化任务中包含此类型的模型。 |
|
spring.ai.ollama.init.chat.additional-models |
除了通过默认属性配置的模型外,还需要初始化的其他模型。 |
|
聊天属性
|
聊天自动配置的启用和禁用现在通过以 要启用,请设置 spring.ai.model.chat=ollama(默认已启用) 要禁用,请设置 spring.ai.model.chat=none(或任何与 ollama 不匹配的值) 此更改是为了允许配置多个模型。 |
前缀 spring.ai.ollama.chat.options 是配置 Ollama 聊天模型的属性前缀。它包括 Ollama 请求(高级)参数,例如 model、keep-alive 和 format,以及 Ollama 模型 options 属性。
以下是 Ollama 聊天模型的高级请求参数
财产 |
描述 |
默认值 |
spring.ai.ollama.chat.enabled (已删除且不再有效) |
启用 Ollama 聊天模型。 |
true |
spring.ai.model.chat |
启用 Ollama 聊天模型。 |
ollama |
spring.ai.ollama.chat.options.model |
要使用的支持的模型名称。 |
mistral |
spring.ai.ollama.chat.options.format |
返回响应的格式。目前,唯一接受的值是 |
- |
spring.ai.ollama.chat.options.keep_alive |
控制模型在请求后在内存中加载的时间 |
5m |
其余的 options 属性基于 Ollama 有效参数和值 以及 Ollama 类型。默认值基于 Ollama 类型默认值。
财产 |
描述 |
默认值 |
spring.ai.ollama.chat.options.numa |
是否使用 NUMA。 |
假 |
spring.ai.ollama.chat.options.num-ctx |
设置用于生成下一个标记的上下文窗口大小。 |
2048 |
spring.ai.ollama.chat.options.num-batch |
提示处理最大批次大小。 |
512 |
spring.ai.ollama.chat.options.num-gpu |
发送到 GPU 的层数。在 macOS 上,默认为 1 以启用 metal 支持,0 为禁用。这里的 1 表示 NumGPU 应动态设置 |
-1 |
spring.ai.ollama.chat.options.main-gpu |
当使用多个 GPU 时,此选项控制哪个 GPU 用于小张量,因为将计算拆分到所有 GPU 的开销不值得。该 GPU 将使用稍微更多的 VRAM 来存储临时结果的暂存缓冲区。 |
0 |
spring.ai.ollama.chat.options.low-vram |
- |
假 |
spring.ai.ollama.chat.options.f16-kv |
- |
true |
spring.ai.ollama.chat.options.logits-all |
返回所有标记的 logits,而不仅仅是最后一个。要使补全返回 logprobs,此项必须为 true。 |
- |
spring.ai.ollama.chat.options.vocab-only |
仅加载词汇,不加载权重。 |
- |
spring.ai.ollama.chat.options.use-mmap |
默认情况下,模型被映射到内存中,这允许系统根据需要加载模型的必要部分。然而,如果模型大于您的总 RAM 量或您的系统可用内存不足,使用 mmap 可能会增加页面换出的风险,从而对性能产生负面影响。禁用 mmap 会导致加载时间变慢,但如果您不使用 mlock,可能会减少页面换出。请注意,如果模型大于总 RAM 量,关闭 mmap 将阻止模型完全加载。 |
null |
spring.ai.ollama.chat.options.use-mlock |
将模型锁定在内存中,防止在内存映射时被交换出去。这可以提高性能,但通过需要更多 RAM 来运行并可能减慢模型加载到 RAM 中的时间,从而牺牲了内存映射的一些优势。 |
假 |
spring.ai.ollama.chat.options.num-thread |
设置计算过程中使用的线程数。默认情况下,Ollama 将检测以实现最佳性能。建议将此值设置为系统物理 CPU 核心数(而不是逻辑核心数)。0 = 让运行时决定 |
0 |
spring.ai.ollama.chat.options.num-keep |
- |
4 |
spring.ai.ollama.chat.options.seed |
设置用于生成随机数的种子。将其设置为特定数字将使模型为相同的提示生成相同的文本。 |
-1 |
spring.ai.ollama.chat.options.num-predict |
生成文本时预测的最大标记数。(-1 = 无限生成,-2 = 填充上下文) |
-1 |
spring.ai.ollama.chat.options.top-k |
降低生成无意义内容的概率。较高的值(例如 100)将提供更多样化的答案,而较低的值(例如 10)将更保守。 |
40 |
spring.ai.ollama.chat.options.top-p |
与 top-k 协同工作。较高的值(例如 0.95)将导致更多样化的文本,而较低的值(例如 0.5)将生成更集中和保守的文本。 |
0.9 |
spring.ai.ollama.chat.options.min-p |
top_p 的替代方案,旨在确保质量和多样性的平衡。参数 p 表示被考虑的标记的最小概率,相对于最有可能的标记的概率。例如,当 p=0.05 且最有可能的标记的概率为 0.9 时,值小于 0.045 的 logits 将被过滤掉。 |
0.0 |
spring.ai.ollama.chat.options.tfs-z |
无尾采样用于减少不太可能出现的标记对输出的影响。较高的值(例如 2.0)将更大程度地减少影响,而值为 1.0 则禁用此设置。 |
1.0 |
spring.ai.ollama.chat.options.typical-p |
- |
1.0 |
spring.ai.ollama.chat.options.repeat-last-n |
设置模型向前查看的距离以防止重复。(默认值:64,0 = 禁用,-1 = num_ctx) |
64 |
spring.ai.ollama.chat.options.temperature |
模型的温度。提高温度将使模型回答更具创意。 |
0.8 |
spring.ai.ollama.chat.options.repeat-penalty |
设置惩罚重复的强度。较高的值(例如 1.5)将更强烈地惩罚重复,而较低的值(例如 0.9)将更宽松。 |
1.1 |
spring.ai.ollama.chat.options.presence-penalty |
- |
0.0 |
spring.ai.ollama.chat.options.frequency-penalty |
- |
0.0 |
spring.ai.ollama.chat.options.mirostat |
启用 Mirostat 采样以控制困惑度。(默认值:0,0 = 禁用,1 = Mirostat,2 = Mirostat 2.0) |
0 |
spring.ai.ollama.chat.options.mirostat-tau |
控制输出的连贯性和多样性之间的平衡。较低的值将导致更集中和连贯的文本。 |
5.0 |
spring.ai.ollama.chat.options.mirostat-eta |
影响算法对生成文本反馈的响应速度。较低的学习率会导致调整较慢,而较高的学习率将使算法更具响应性。 |
0.1 |
spring.ai.ollama.chat.options.penalize-newline |
- |
true |
spring.ai.ollama.chat.options.stop |
设置要使用的停止序列。当遇到此模式时,LLM 将停止生成文本并返回。可以通过在模型文件中指定多个单独的停止参数来设置多个停止模式。 |
- |
spring.ai.ollama.chat.options.tool-names |
工具列表,通过其名称标识,用于在单个提示请求中启用函数调用。具有这些名称的工具必须存在于 ToolCallback 注册表中。 |
- |
spring.ai.ollama.chat.options.tool-callbacks |
要注册到 ChatModel 的工具回调。 |
- |
spring.ai.ollama.chat.options.internal-tool-execution-enabled |
如果为 false,Spring AI 将不会在内部处理工具调用,而是将其代理到客户端。然后,客户端负责处理工具调用,将其分派到适当的函数,并返回结果。如果为 true(默认),Spring AI 将在内部处理函数调用。仅适用于支持函数调用的聊天模型 |
true |
所有以 spring.ai.ollama.chat.options 为前缀的属性都可以在运行时通过向 Prompt 调用添加特定于请求的 运行时选项 来覆盖。 |
运行时选项
OllamaChatOptions.java 类提供了模型配置,例如要使用的模型、温度、思考模式等。
OllamaOptions 类已被弃用。聊天模型请使用 OllamaChatOptions,嵌入模型请使用 OllamaEmbeddingOptions。新类提供类型安全、模型特定的配置选项。 |
在启动时,可以使用 OllamaChatModel(api, options) 构造函数或 spring.ai.ollama.chat.options.* 属性配置默认选项。
在运行时,您可以通过向 Prompt 调用添加新的、请求特定的选项来覆盖默认选项。例如,要为特定请求覆盖默认模型和温度
ChatResponse response = chatModel.call(
new Prompt(
"Generate the names of 5 famous pirates.",
OllamaChatOptions.builder()
.model(OllamaModel.LLAMA3_1)
.temperature(0.4)
.build()
));| 除了模型特定的 OllamaChatOptions,您还可以使用可移植的 ChatOptions 实例,通过 ChatOptions#builder() 创建。 |
自动拉取模型
Spring AI Ollama 可以在您的 Ollama 实例中没有模型时自动拉取模型。此功能对于开发和测试以及将应用程序部署到新环境特别有用。
| 您还可以按名称拉取数千个免费的 GGUF Hugging Face 模型。 |
拉取模型有三种策略:
-
always(定义在PullModelStrategy.ALWAYS中):始终拉取模型,即使它已经可用。这有助于确保您使用的是最新版本的模型。 -
when_missing(定义在PullModelStrategy.WHEN_MISSING中):仅当模型尚不可用时才拉取。这可能导致使用旧版本的模型。 -
never(定义在PullModelStrategy.NEVER中):从不自动拉取模型。
| 由于下载模型可能存在延迟,因此不建议在生产环境中使用自动拉取。相反,请考虑提前评估并预下载必要的模型。 |
所有通过配置属性和默认选项定义的模型都可以在启动时自动拉取。您可以使用配置属性来配置拉取策略、超时和最大重试次数
spring:
ai:
ollama:
init:
pull-model-strategy: always
timeout: 60s
max-retries: 1| 应用程序将不会完成其初始化,直到 Ollama 中所有指定的模型都可用。根据模型大小和互联网连接速度,这可能会显著减慢应用程序的启动时间。 |
您可以在启动时初始化其他模型,这对于在运行时动态使用的模型很有用。
spring:
ai:
ollama:
init:
pull-model-strategy: always
chat:
additional-models:
- llama3.2
- qwen2.5如果您只想将拉取策略应用于特定类型的模型,可以将聊天模型从初始化任务中排除
spring:
ai:
ollama:
init:
pull-model-strategy: always
chat:
include: false此配置将对所有模型(聊天模型除外)应用拉取策略。
函数调用
您可以使用 OllamaChatModel 注册自定义 Java 函数,并让 Ollama 模型智能地选择输出一个包含调用一个或多个注册函数参数的 JSON 对象。这是一种将 LLM 功能与外部工具和 API 连接的强大技术。阅读更多关于 工具调用 的信息。
| 您需要 Ollama 0.2.8 或更高版本才能使用功能调用功能,以及 Ollama 0.4.6 或更高版本才能在流模式下使用它们。 |
思考模式(推理)
Ollama 支持思考模式,用于可以发出其内部推理过程,然后提供最终答案的推理模型。此功能适用于 Qwen3、DeepSeek-v3.1、DeepSeek R1 和 GPT-OSS 等模型。
| 思考模式可帮助您理解模型的推理过程,并可提高复杂问题的响应质量。 |
默认行为(Ollama 0.12+):具有思考能力的模型(例如 qwen3:*-thinking、deepseek-r1、deepseek-v3.1)在未明确设置思考选项时,默认自动启用思考。标准模型(例如 qwen2.5:*、llama3.2)默认不启用思考。要明确控制此行为,请使用 .enableThinking() 或 .disableThinking()。 |
启用思考模式
大多数模型(Qwen3、DeepSeek-v3.1、DeepSeek R1)支持简单的布尔值启用/禁用
ChatResponse response = chatModel.call(
new Prompt(
"How many letter 'r' are in the word 'strawberry'?",
OllamaChatOptions.builder()
.model("qwen3")
.enableThinking()
.build()
));
// Access the thinking process
String thinking = response.getResult().getMetadata().get("thinking");
String answer = response.getResult().getOutput().getContent();您也可以明确禁用思考
ChatResponse response = chatModel.call(
new Prompt(
"What is 2+2?",
OllamaChatOptions.builder()
.model("deepseek-r1")
.disableThinking()
.build()
));思考级别(仅限 GPT-OSS)
GPT-OSS 模型需要明确的思考级别,而不是布尔值。
// Low thinking level
ChatResponse response = chatModel.call(
new Prompt(
"Generate a short headline",
OllamaChatOptions.builder()
.model("gpt-oss")
.thinkLow()
.build()
));
// Medium thinking level
ChatResponse response = chatModel.call(
new Prompt(
"Analyze this dataset",
OllamaChatOptions.builder()
.model("gpt-oss")
.thinkMedium()
.build()
));
// High thinking level
ChatResponse response = chatModel.call(
new Prompt(
"Solve this complex problem",
OllamaChatOptions.builder()
.model("gpt-oss")
.thinkHigh()
.build()
));访问思考内容
思考内容可在响应元数据中获取
ChatResponse response = chatModel.call(
new Prompt(
"Calculate 17 × 23",
OllamaChatOptions.builder()
.model("deepseek-r1")
.enableThinking()
.build()
));
// Get the reasoning process
String thinking = response.getResult().getMetadata().get("thinking");
System.out.println("Reasoning: " + thinking);
// Output: "17 × 20 = 340, 17 × 3 = 51, 340 + 51 = 391"
// Get the final answer
String answer = response.getResult().getOutput().getContent();
System.out.println("Answer: " + answer);
// Output: "The answer is 391"流式传输与思考
思考模式也适用于流式响应
Flux<ChatResponse> stream = chatModel.stream(
new Prompt(
"Explain quantum entanglement",
OllamaChatOptions.builder()
.model("qwen3")
.enableThinking()
.build()
));
stream.subscribe(response -> {
String thinking = response.getResult().getMetadata().get("thinking");
String content = response.getResult().getOutput().getContent();
if (thinking != null && !thinking.isEmpty()) {
System.out.println("[Thinking] " + thinking);
}
if (content != null && !content.isEmpty()) {
System.out.println("[Response] " + content);
}
});当禁用思考或未设置时,thinking 元数据字段将为 null 或为空。 |
多模态
多模态是指模型同时理解和处理来自各种来源(包括文本、图像、音频和其他数据格式)信息的能力。
Ollama 中支持多模态的模型包括 LLaVA 和 BakLLaVA(参见完整列表)。有关更多详细信息,请参阅 LLaVA:大型语言和视觉助手。
Ollama 消息 API 提供了一个“images”参数,用于将 base64 编码的图像列表与消息一起包含。
Spring AI 的 Message 接口通过引入 Media 类型来促进多模态 AI 模型。此类型包含消息中媒体附件的数据和详细信息,使用 Spring 的 org.springframework.util.MimeType 和用于原始媒体数据的 org.springframework.core.io.Resource。
以下是一个摘自 OllamaChatModelMultimodalIT.java 的简单代码示例,说明了用户文本与图像的融合。
var imageResource = new ClassPathResource("/multimodal.test.png");
var userMessage = new UserMessage("Explain what do you see on this picture?",
new Media(MimeTypeUtils.IMAGE_PNG, this.imageResource));
ChatResponse response = chatModel.call(new Prompt(this.userMessage,
OllamaChatOptions.builder().model(OllamaModel.LLAVA)).build());该示例显示了一个模型将 multimodal.test.png 图像作为输入

以及文本消息“解释你在这张图片上看到了什么?”,并生成如下响应
The image shows a small metal basket filled with ripe bananas and red apples. The basket is placed on a surface, which appears to be a table or countertop, as there's a hint of what seems like a kitchen cabinet or drawer in the background. There's also a gold-colored ring visible behind the basket, which could indicate that this photo was taken in an area with metallic decorations or fixtures. The overall setting suggests a home environment where fruits are being displayed, possibly for convenience or aesthetic purposes.
结构化输出
Ollama 提供了自定义的 结构化输出 API,可确保您的模型生成严格符合您提供的 JSON Schema 的响应。除了现有的 Spring AI 模型无关的 结构化输出转换器 之外,这些 API 提供了增强的控制和精度。
配置
Spring AI 允许您使用 OllamaChatOptions 构建器以编程方式配置响应格式。
使用聊天选项构建器
您可以使用 OllamaChatOptions 构建器以编程方式设置响应格式,如下所示:
String jsonSchema = """
{
"type": "object",
"properties": {
"steps": {
"type": "array",
"items": {
"type": "object",
"properties": {
"explanation": { "type": "string" },
"output": { "type": "string" }
},
"required": ["explanation", "output"],
"additionalProperties": false
}
},
"final_answer": { "type": "string" }
},
"required": ["steps", "final_answer"],
"additionalProperties": false
}
""";
Prompt prompt = new Prompt("how can I solve 8x + 7 = -23",
OllamaChatOptions.builder()
.model(OllamaModel.LLAMA3_2.getName())
.format(new ObjectMapper().readValue(jsonSchema, Map.class))
.build());
ChatResponse response = this.ollamaChatModel.call(this.prompt);与 BeanOutputConverter 实用程序集成
您可以利用现有的 BeanOutputConverter 实用程序从您的领域对象自动生成 JSON Schema,然后将结构化响应转换为领域特定的实例。
record MathReasoning(
@JsonProperty(required = true, value = "steps") Steps steps,
@JsonProperty(required = true, value = "final_answer") String finalAnswer) {
record Steps(
@JsonProperty(required = true, value = "items") Items[] items) {
record Items(
@JsonProperty(required = true, value = "explanation") String explanation,
@JsonProperty(required = true, value = "output") String output) {
}
}
}
var outputConverter = new BeanOutputConverter<>(MathReasoning.class);
Prompt prompt = new Prompt("how can I solve 8x + 7 = -23",
OllamaChatOptions.builder()
.model(OllamaModel.LLAMA3_2.getName())
.format(outputConverter.getJsonSchemaMap())
.build());
ChatResponse response = this.ollamaChatModel.call(this.prompt);
String content = this.response.getResult().getOutput().getText();
MathReasoning mathReasoning = this.outputConverter.convert(this.content);请务必使用 @JsonProperty(required = true,...) 注解来生成一个准确标记字段为 required 的模式。尽管这对于 JSON Schema 来说是可选的,但建议用于结构化响应以正常工作。 |
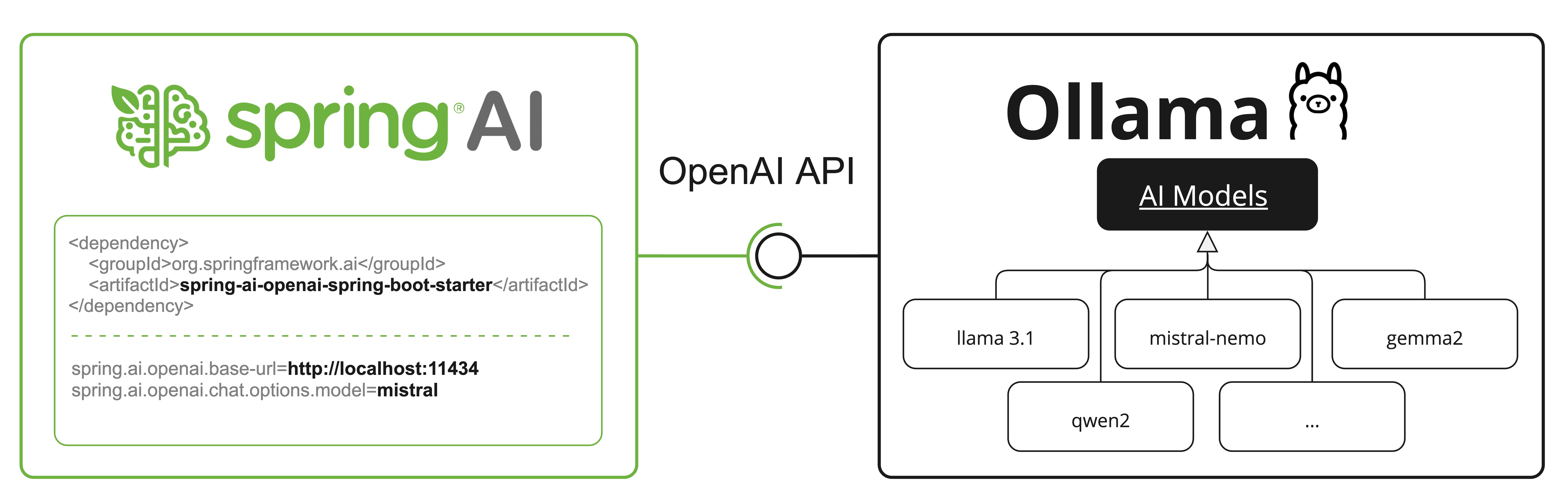
OpenAI API 兼容性
Ollama 与 OpenAI API 兼容,您可以使用 Spring AI OpenAI 客户端与 Ollama 对话并使用工具。为此,您需要将 OpenAI 的基本 URL 配置为您的 Ollama 实例:spring.ai.openai.chat.base-url=https://:11434,并选择一个提供的 Ollama 模型:spring.ai.openai.chat.options.model=mistral。
当使用 OpenAI 客户端与 Ollama 时,您可以使用 extraBody 选项 传递 Ollama 特定的参数(例如 top_k、repeat_penalty、num_predict)。这允许您在使用 OpenAI 客户端的同时,利用 Ollama 的全部功能。 |
通过 OpenAI 兼容性获取推理内容
Ollama 的 OpenAI 兼容端点支持用于具有思考能力模型(如 qwen3:*-thinking、deepseek-r1、deepseek-v3.1)的 reasoning_content 字段。当使用 Spring AI OpenAI 客户端与 Ollama 时,模型的推理过程会自动捕获并通过响应元数据提供。
这是使用 Ollama 原生思考模式 API(如上文 思考模式(推理) 中所述)的替代方案。两种方法都适用于 Ollama 的思考模型,但 OpenAI 兼容端点使用 reasoning_content 字段名而不是 thinking。 |
以下是通过 OpenAI 客户端访问 Ollama 推理内容的示例
// Configure Spring AI OpenAI client to point to Ollama
@Configuration
class OllamaConfig {
@Bean
OpenAiChatModel ollamaChatModel() {
var openAiApi = new OpenAiApi("https://:11434", "ollama");
return new OpenAiChatModel(openAiApi,
OpenAiChatOptions.builder()
.model("deepseek-r1") // or qwen3, deepseek-v3.1, etc.
.build());
}
}
// Use the model with thinking-capable models
ChatResponse response = chatModel.call(
new Prompt("How many letter 'r' are in the word 'strawberry'?"));
// Access the reasoning process from metadata
String reasoning = response.getResult().getMetadata().get("reasoningContent");
if (reasoning != null && !reasoning.isEmpty()) {
System.out.println("Model's reasoning process:");
System.out.println(reasoning);
}
// Get the final answer
String answer = response.getResult().getOutput().getContent();
System.out.println("Answer: " + answer);| Ollama 中具有思考能力的模型(0.12+)在通过 OpenAI 兼容端点访问时会自动启用思考模式。推理内容会自动捕获,无需额外配置。 |
请查看 OllamaWithOpenAiChatModelIT.java 测试,了解如何通过 Spring AI OpenAI 使用 Ollama 的示例。
HuggingFace 模型
Ollama 可以即时访问所有 GGUF Hugging Face 聊天模型。您可以通过名称拉取这些模型:ollama pull hf.co/<username>/<model-repository>,或配置自动拉取策略:自动拉取模型
spring.ai.ollama.chat.options.model=hf.co/bartowski/gemma-2-2b-it-GGUF
spring.ai.ollama.init.pull-model-strategy=always-
spring.ai.ollama.chat.options.model:指定要使用的 Hugging Face GGUF 模型。 -
spring.ai.ollama.init.pull-model-strategy=always:(可选)在启动时启用自动模型拉取。对于生产环境,您应该预先下载模型以避免延迟:ollama pull hf.co/bartowski/gemma-2-2b-it-GGUF。
示例控制器
创建一个新的 Spring Boot 项目,并将 spring-ai-starter-model-ollama 添加到您的 pom(或 gradle)依赖项中。
在 src/main/resources 目录下添加一个 application.yaml 文件,以启用和配置 Ollama 聊天模型
spring:
ai:
ollama:
base-url: https://:11434
chat:
options:
model: mistral
temperature: 0.7将 base-url 替换为您的 Ollama 服务器 URL。 |
这将创建一个 OllamaChatModel 实现,您可以将其注入到您的类中。这是一个简单的 @RestController 类的示例,它使用聊天模型进行文本生成。
@RestController
public class ChatController {
private final OllamaChatModel chatModel;
@Autowired
public ChatController(OllamaChatModel chatModel) {
this.chatModel = chatModel;
}
@GetMapping("/ai/generate")
public Map<String,String> generate(@RequestParam(value = "message", defaultValue = "Tell me a joke") String message) {
return Map.of("generation", this.chatModel.call(message));
}
@GetMapping("/ai/generateStream")
public Flux<ChatResponse> generateStream(@RequestParam(value = "message", defaultValue = "Tell me a joke") String message) {
Prompt prompt = new Prompt(new UserMessage(message));
return this.chatModel.stream(prompt);
}
}手动配置
如果您不想使用 Spring Boot 自动配置,可以在应用程序中手动配置 OllamaChatModel。OllamaChatModel 实现了 ChatModel 和 StreamingChatModel,并使用 低级 OllamaApi 客户端 连接到 Ollama 服务。
要使用它,请将 spring-ai-ollama 依赖项添加到您的项目的 Maven pom.xml 或 Gradle build.gradle 构建文件中
-
Maven
-
Gradle
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-ollama</artifactId>
</dependency>dependencies {
implementation 'org.springframework.ai:spring-ai-ollama'
}| 请参阅 依赖项管理 部分,将 Spring AI BOM 添加到您的构建文件中。 |
spring-ai-ollama 依赖项还提供了对 OllamaEmbeddingModel 的访问。有关 OllamaEmbeddingModel 的更多信息,请参阅 Ollama 嵌入模型 部分。 |
接下来,创建一个 OllamaChatModel 实例并使用它发送文本生成请求。
var ollamaApi = OllamaApi.builder().build();
var chatModel = OllamaChatModel.builder()
.ollamaApi(ollamaApi)
.defaultOptions(
OllamaChatOptions.builder()
.model(OllamaModel.MISTRAL)
.temperature(0.9)
.build())
.build();
ChatResponse response = this.chatModel.call(
new Prompt("Generate the names of 5 famous pirates."));
// Or with streaming responses
Flux<ChatResponse> response = this.chatModel.stream(
new Prompt("Generate the names of 5 famous pirates."));OllamaChatOptions 提供了所有聊天请求的配置信息。
低级 OllamaApi 客户端
OllamaApi 为 Ollama 聊天完成 API Ollama 聊天完成 API 提供了一个轻量级 Java 客户端。
以下类图说明了 OllamaApi 聊天接口和构建块
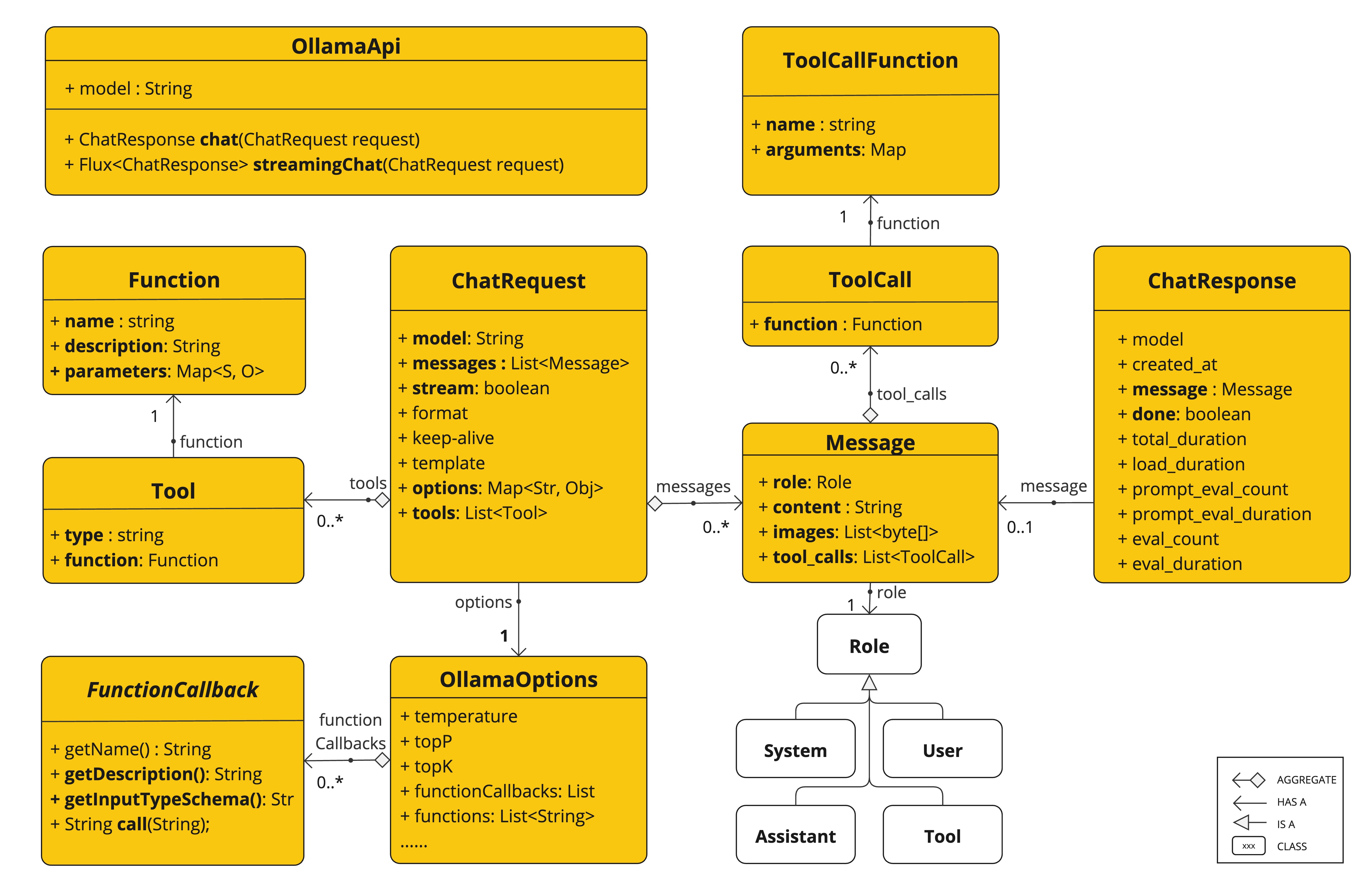
OllamaApi 是一个低级 API,不建议直接使用。请改用 OllamaChatModel。 |
这里有一个简单的代码片段,展示了如何以编程方式使用 API
OllamaApi ollamaApi = new OllamaApi("YOUR_HOST:YOUR_PORT");
// Sync request
var request = ChatRequest.builder("orca-mini")
.stream(false) // not streaming
.messages(List.of(
Message.builder(Role.SYSTEM)
.content("You are a geography teacher. You are talking to a student.")
.build(),
Message.builder(Role.USER)
.content("What is the capital of Bulgaria and what is the size? "
+ "What is the national anthem?")
.build()))
.options(OllamaChatOptions.builder().temperature(0.9).build())
.build();
ChatResponse response = this.ollamaApi.chat(this.request);
// Streaming request
var request2 = ChatRequest.builder("orca-mini")
.ttream(true) // streaming
.messages(List.of(Message.builder(Role.USER)
.content("What is the capital of Bulgaria and what is the size? " + "What is the national anthem?")
.build()))
.options(OllamaChatOptions.builder().temperature(0.9).build().toMap())
.build();
Flux<ChatResponse> streamingResponse = this.ollamaApi.streamingChat(this.request2);
